본 시리즈는 가시다님의 AEWS(AWS EKS Workshop) 1기 진행 내용입니다. (가시다님 노션)
스터디에 사용되는 링크 (AWS EKS Workshop)
목차
1. Logging in EKS
2. Container Insights metrics in Amazon CloudWatch & Fluent Bit (Logs)
3. Metrics-server & kwatch & botkube
4. 프로메테우스-스택
5. 그라파나 Grafana
6. kubecost
EKS 클러스터 세팅 (Cloudformation)
https://s3.ap-northeast-2.amazonaws.com/cloudformation.cloudneta.net/K8S/eks-oneclick3.yaml
1. Logging in EKS
CloudWatch로그에 쿠버네티스 control plane 로그를 저장하는 실습이다.
Control Plane logging : 로그 이름( /aws/eks/<cluster-name>/cluster ) - Docs
- Kubernetes API server component logs (api) – kube-apiserver-<nnn...>
- Audit (audit) – kube-apiserver-audit-<nnn...>
- Authenticator (authenticator) – authenticator-<nnn...>
- Controller manager (controllerManager) – kube-controller-manager-<nnn...>
- Scheduler (scheduler) – kube-scheduler-<nnn...>
# 모든 로깅 활성화
aws eks update-cluster-config --region $AWS_DEFAULT_REGION --name $CLUSTER_NAME \
--logging '{"clusterLogging":[{"types":["api","audit","authenticator","controllerManager","scheduler"],"enabled":true}]}'
# 로그 그룹 확인
aws logs describe-log-groups | jq
# 로그 tail 확인 : aws logs tail help
aws logs tail /aws/eks/$CLUSTER_NAME/cluster | more
# 신규 로그를 바로 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --follow
# 필터 패턴
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --filter-pattern <필터 패턴>
# 로그 스트림이름
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix <로그 스트림 prefix> --follow
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --log-stream-name-prefix kube-controller-manager --follow
kubectl scale deployment -n kube-system coredns --replicas=1
kubectl scale deployment -n kube-system coredns --replicas=2
# 시간 지정: 1초(s) 1분(m) 1시간(h) 하루(d) 한주(w)
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m
# 짧게 출력
aws logs tail /aws/eks/$CLUSTER_NAME/cluster --since 1h30m --format short
aws eks update-cluster-config 를 수행하면 아래와 같이 변경된다.

cloudwatch에서 확인


CLI로 확인할 경우 신규 로그는 대략 이렇게 출력된다. (tail)
- CloudWatch Log Insights - 링크
# EC2 Instance가 NodeNotReady 상태인 로그 검색
fields @timestamp, @message
| filter @message like /NodeNotReady/
| sort @timestamp desc
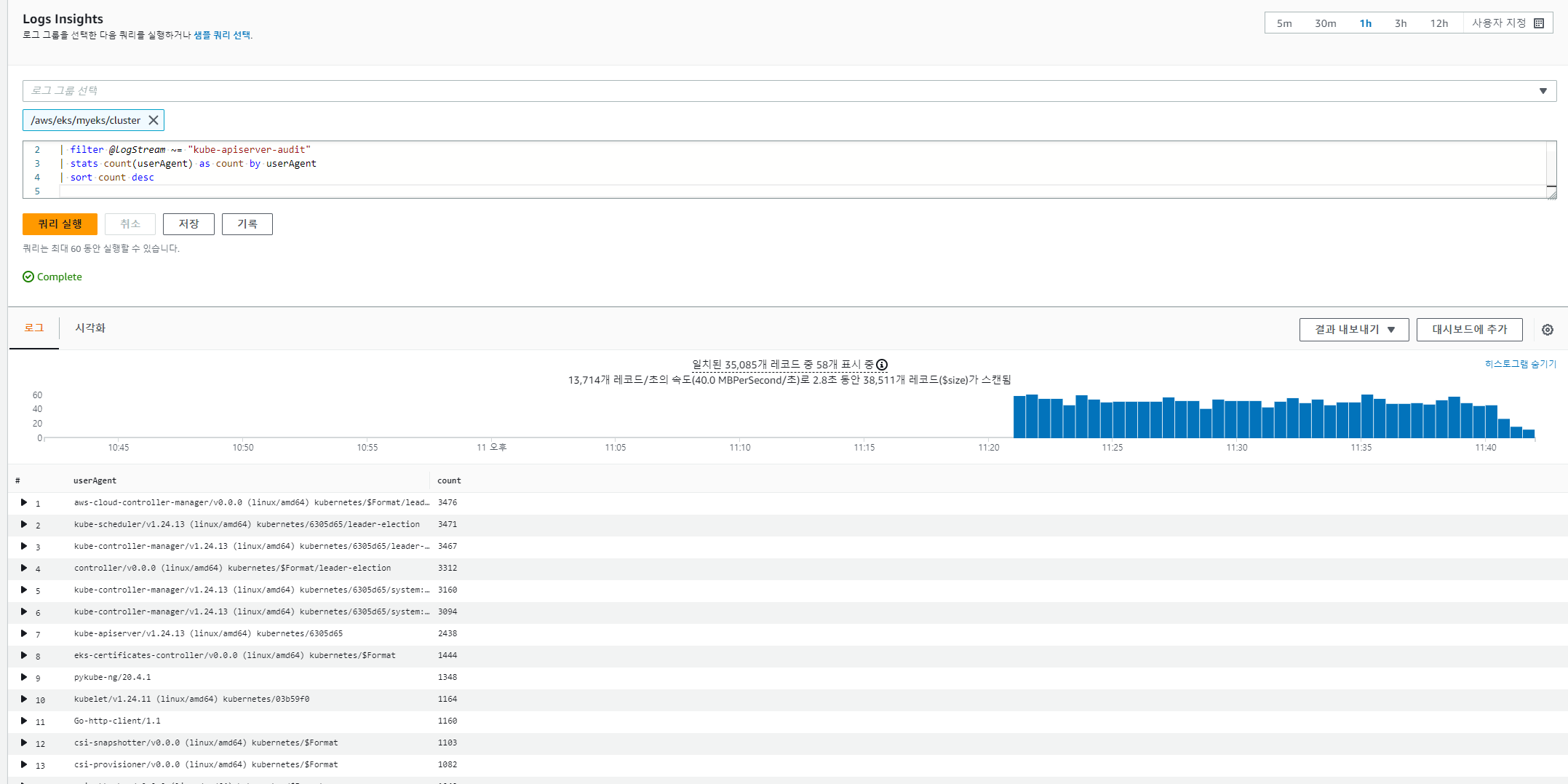
# kube-apiserver-audit 로그에서 userAgent 정렬해서 아래 4개 필드 정보 검색
fields userAgent, requestURI, @timestamp, @message
| filter @logStream ~= "kube-apiserver-audit"
| stats count(userAgent) as count by userAgent
| sort count desc
# kube-scheduler 로그 확인
fields @timestamp, @message
| filter @logStream ~= "kube-scheduler"
| sort @timestamp desc
# authenticator 로그 확인
fields @timestamp, @message
| filter @logStream ~= "authenticator"
| sort @timestamp desc
# kube-controller-manager 로그 확인
fields @timestamp, @message
| filter @logStream ~= "kube-controller-manager"
| sort @timestamp desc
# CW Logs Insights 쿼리
fields @timestamp, @message, @logStream
| filter @logStream like /kube-apiserver-audit/
| filter @message like /mvcc: database space exceeded/
| limit 10
# How do I identify what is consuming etcd database space?
kubectl get --raw=/metrics | grep apiserver_storage_objects |awk '$2>100' |sort -g -k 2
kubectl get --raw=/metrics | grep apiserver_storage_objects |awk '$2>50' |sort -g -k 2
apiserver_storage_objects{resource="clusterrolebindings.rbac.authorization.k8s.io"} 78
apiserver_storage_objects{resource="clusterroles.rbac.authorization.k8s.io"} 92
# CW Logs Insights 쿼리 : Request volume - Requests by User Agent:
fields userAgent, requestURI, @timestamp, @message
| filter @logStream like /kube-apiserver-audit/
| stats count(*) as count by userAgent
| sort count desc
# CW Logs Insights 쿼리 : Request volume - Requests by Universal Resource Identifier (URI)/Verb:
filter @logStream like /kube-apiserver-audit/
| stats count(*) as count by requestURI, verb, user.username
| sort count desc
# Object revision updates
fields requestURI
| filter @logStream like /kube-apiserver-audit/
| filter requestURI like /pods/
| filter verb like /patch/
| filter count > 8
| stats count(*) as count by requestURI, responseStatus.code
| filter responseStatus.code not like /500/
| sort count desc
#
fields @timestamp, userAgent, responseStatus.code, requestURI
| filter @logStream like /kube-apiserver-audit/
| filter requestURI like /pods/
| filter verb like /patch/
| filter requestURI like /name_of_the_pod_that_is_updating_fast/
| sort @timestamp
- 로깅 끄기
# EKS Control Plane 로깅(CloudWatch Logs) 비활성화
eksctl utils update-cluster-logging --cluster $CLUSTER_NAME --region $AWS_DEFAULT_REGION --disable-types all --approve
# 로그 그룹 삭제
aws logs delete-log-group --log-group-name /aws/eks/$CLUSTER_NAME/cluster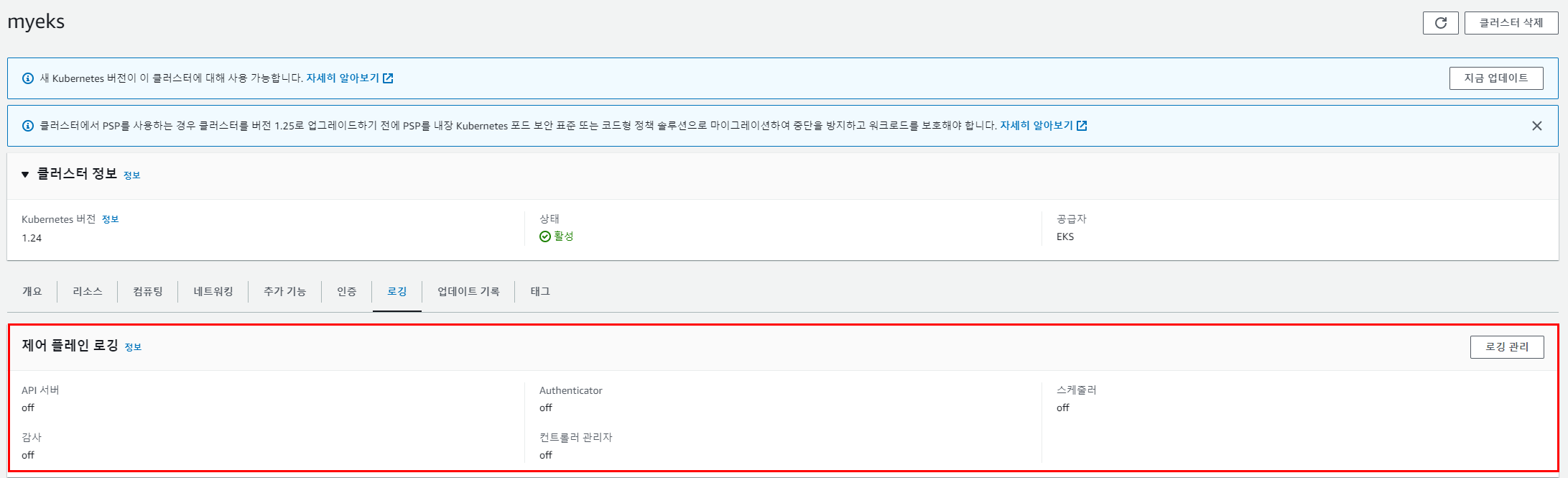
Control Plane metrics with Prometheus & CW Logs Insights 쿼리 - Docs
# 메트릭 패턴 정보 : metric_name{"tag"="value"[,...]} value
kubectl get --raw /metrics | more- 프로메테우스에서 확인하던 메트릭 양식과 비슷하게 나옴

Managing etcd database size on Amazon EKS clusters - 링크
# etcd 데이터 용량 확인
kubectl get --raw /metrics | grep "etcd_db_total_size_in_bytes"
etcd_db_total_size_in_bytes{endpoint="http://10.0.160.16:2379"} 4.665344e+06
etcd_db_total_size_in_bytes{endpoint="http://10.0.32.16:2379"} 4.636672e+06
etcd_db_total_size_in_bytes{endpoint="http://10.0.96.16:2379"} 4.640768e+06
# etcd 에 저장된 개체 수 확인 (1.22버전 이상)
kubectl get --raw=/metrics | grep apiserver_storage_objects |awk '$2>100' |sort -g -k 2
# etcd 에 저장된 개체 수 확인 (1.21버전 이하)
kubectl get --raw=/metrics | grep etcd_object_counts |awk '$2>100' |sort -g -k 2


컨테이너(파드) 로깅
NGINX 웹서버 배포 - Helm
# NGINX 웹서버 배포
helm repo add bitnami https://charts.bitnami.com/bitnami
# 사용 리전의 인증서 ARN 확인
CERT_ARN=$(aws acm list-certificates --query 'CertificateSummaryList[].CertificateArn[]' --output text)
echo $CERT_ARN
# 도메인 확인
echo $MyDomain
# 파라미터 파일 생성
cat <<EOT > nginx-values.yaml
service:
type: NodePort
ingress:
enabled: true
ingressClassName: alb
hostname: nginx.$MyDomain
path: /*
annotations:
alb.ingress.kubernetes.io/scheme: internet-facing
alb.ingress.kubernetes.io/target-type: ip
alb.ingress.kubernetes.io/listen-ports: '[{"HTTPS":443}, {"HTTP":80}]'
alb.ingress.kubernetes.io/certificate-arn: $CERT_ARN
alb.ingress.kubernetes.io/success-codes: 200-399
alb.ingress.kubernetes.io/load-balancer-name: $CLUSTER_NAME-ingress-alb
alb.ingress.kubernetes.io/group.name: study
alb.ingress.kubernetes.io/ssl-redirect: '443'
EOT
cat nginx-values.yaml | yh
# 배포
helm install nginx bitnami/nginx --version 14.1.0 -f nginx-values.yaml
# 확인
kubectl get ingress,deploy,svc,ep nginx
kubectl get targetgroupbindings # ALB TG 확인
# 접속 주소 확인 및 접속
echo -e "Nginx WebServer URL = https://nginx.$MyDomain"
curl -s https://nginx.$MyDomain
kubectl logs deploy/nginx -f
# 반복 접속
while true; do curl -s https://nginx.$MyDomain -I | head -n 1; date; sleep 1; done
# (참고) 삭제 시
helm uninstall nginx


컨테이너 로그 환경의 로그는 표준 출력 stdout과 표준 에러 stderr로 보내는 것을 권고 - 링크
- 해당 권고에 따라 작성된 컨테이너 애플리케이션의 로그는 해당 파드 안으로 접속하지 않아도 사용자는 외부에서 kubectl logs 명령어로 애플리케이션 종류에 상관없이, 애플리케이션마다 로그 파일 위치에 상관없이, 단일 명령어로 조회 가능
# 로그 모니터링
kubectl logs deploy/nginx -f
# nginx 웹 접속 시도
# 컨테이너 로그 파일 위치 확인
kubectl exec -it deploy/nginx -- ls -l /opt/bitnami/nginx/logs/
total 0
lrwxrwxrwx 1 root root 11 Feb 18 13:35 access.log -> /dev/stdout
lrwxrwxrwx 1 root root 11 Feb 18 13:35 error.log -> /dev/stderr
(참고) nginx docker log collector 예시 - 링크 링크
RUN ln -sf /dev/stdout /opt/bitnami/nginx/logs/access.log
RUN ln -sf /dev/stderr /opt/bitnami/nginx/logs/error.log
# forward request and error logs to docker log collector
RUN ln -sf /dev/stdout /var/log/nginx/access.log \
&& ln -sf /dev/stderr /var/log/nginx/error.log- 또한 종료된 파드의 로그는 kubectl logs로 조회 할 수 없다
- kubelet 기본 설정은 로그 파일의 최대 크기가 10Mi로 10Mi를 초과하는 로그는 전체 로그 조회가 불가능함
cat /etc/kubernetes/kubelet-config.yaml
...
containerLogMaxSize: 10Mi이건 추후에..
파드 로깅 : CloudWatch Container Insights + Fluent Bit로 파드 로그 수집 가능 ⇒ 다음 장에서 메트릭과 함께 다룸
결론
파드 로그를 표준출력(stdout)과 표준에러(stderr)로 보내야 하는 이유
1. 분리된 로그 스트림
- 로그를 표준 출력과 표준 에러로 분리하면, 애플리케이션의 정상적인 출력과 예외 또는 오류 메시지를 구분
- 이를 통해 로그를 보다 쉽게 필터링하고 분석
2. 로그의 우선순위와 처리: 많은 로깅 시스템은 표준 출력과 표준 에러를 서로 다르게 처리
- ex, 로그 수집 도구나 로그 관리 시스템은 표준 출력을 통해 전달되는 로그를 주의 깊게 모니터링하고 중앙 집중식으로 수집
- 반면, 표준 에러를 통해 전달되는 로그는 오류 또는 예외 상황을 나타내므로 더 높은 우선순위로 처리.
3. 유연한 로그 처리
- 로그를 표준 출력과 표준 에러로 보내면, 컨테이너 환경에서 로그 처리를 유연하게 구성
- ex, 표준 출력을 파일에 기록하거나 로그 관리 도구로 전달
- ex, 표준 에러를 모니터링 시스템으로 보내 경고를 생성하거나 실시간으로 처리
4. 표준화와 호환성
- 많은 프로그래밍 언어와 라이브러리는 로그를 표준 출력과 표준 에러로 보내도록 지원
- 여러 컨테이너 환경에서 로그 처리를 일관되고 표준화된 방식으로 수행 가능




댓글