본 시리즈는 가시다님의 T101(테라폼으로 시작하는 IaC) 3기 진행 내용입니다. (가시다님 노션)
도서 정보
https://www.yes24.com/Product/Goods/119179333
테라폼으로 시작하는 IaC - 예스24
“현업에서 요구하는 진짜 IaC 사용법”테라폼으로 배우는 인프라 운영의 모든 것IaC는 효율적인 데브옵스와 클라우드 자동화 구축을 위해 꼭 필요한 기술로 각광받고 있다. 그중에서도 테라폼
www.yes24.com
실습 코드
https://github.com/terraform101
목차
1. 데이터 소스 및 반복문
2. 입력 변수(Variable) 및 지역값(local)
3. 출력(output)
1. 데이터 소스
데이터 소스란?
테라폼에서 정의되지 않은 외부 리소스 또는 저장된 정보를 테라폼 내에서 참조할 때 사용한다.
데이터 소스가 어떤 것인지 실습을 통해 알아보고, 개인적인 사용 경험도 이야기 해보겠다.
main.tf
data "local_file" "abc" {
filename = "${path.module}/abc.txt"
}데이터 소스를 정의할 때 사용 가능한 메타 인수
- depends_on : 종속성을 선언하며, 선언된 구성요소와의 생성 시점에 대해 정의
- count : 선언된 개수에 따라 여러 리소스를 생성
- for_each : map 또는 set 타입의 데이터 배열의 값을 기준으로 여러 리소스를 생성
- lifecycle : 리소스의 수명주기 관리
data source를 사용하겠다고 정의해두고 파일을 준비하자
# 실습 확인을 위해서 abc.txt 파일 생성
echo "t101 study - 2week" > abc.txt
#
terraform init && terraform plan && terraform apply -auto-approve
terraform state list
# 테라폼 콘솔 : 데이터 소스 참조 확인
echo "data.local_file.abc" | terraform consoleabc.txt 파일을 생성하고 init, plan, apply를 하게되면 state list를 통해서 데이터 소스에 대한 정보를 확인할 수 있다.


데이터 소스 속성 참고
속성 값을 정의하는 방식과 접근하는 방법(참조)
# Terraform Code
data "<리소스 유형>" "<이름>" {
<인수> = <값>
}
# 데이터 소스 참조
data.<리소스 유형>.<이름>.<속성>
코드 예시 : 데이터 소스를 활용해 AWS 가용영역 인수를 정의 → 리전 내에서 사용 가능한 가용영역 목록 가져와서 사용하기
# Declare the data source
data "aws_availability_zones" "available" {
state = "available"
}
resource "aws_subnet" "primary" {
availability_zone = data.aws_availability_zones.available.names[0]
# e.g. ap-northeast-2a
}
resource "aws_subnet" "secondary" {
availability_zone = data.aws_availability_zones.available.names[1]
# e.g. ap-northeast-2b
}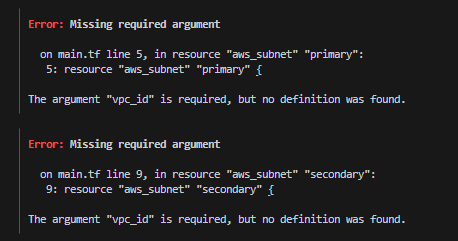
이 에러를 어떻게 해결해야 할까
argument vpc_id가 필요하다고 한다.
우선 aws_availability_zones 데이터 소스를 찾아가보자
https://registry.terraform.io/providers/hashicorp/aws/latest/docs/data-sources/availability_zones
여기서도 vpc_id 는 명시되어 있다.
이걸 넣어줘보자


흠... cidrBlock이 필요하다고 한다. 당연히 서브넷을 만들려면 cidr가 필요하다.
# Declare the data source
data "aws_availability_zones" "available" {
state = "available"
}
data "aws_vpc" "available" {
id = "vpc-0768*********"
}
resource "aws_subnet" "primary" {
vpc_id = data.aws_vpc.available.id
availability_zone = data.aws_availability_zones.available.names[0]
cidr_block = "10.0.1.0/24"
# e.g. ap-northeast-2a
}
resource "aws_subnet" "secondary" {
vpc_id = data.aws_vpc.available.id
availability_zone = data.aws_availability_zones.available.names[1]
cidr_block = "10.0.2.0/24"
# e.g. ap-northeast-2b
}cidr_block을 멋지게 사용하는 방법도 있긴 하더라만... 잘 안되어서 그냥 고정값으로 넣었다.
VPC를 새로 생성했고, data source로 aws_vpc를 지정했다.

그 후 aws_subnet 생성

개인적인 data source 활용 사례.
클라우드를 처음 접하고 이를 Portal, 스크립트언어(CLI, PowerShell), Terraform으로 배포한 적이 있었다.
배포하는 리소스가 늘어날수록 배포는 되어도 관련된 값(IP 등등)이 output으로 나오지 않고 NULL값이 발생하는 경우가 있었다.
이 때 배포하고나서 data source로 정보를 다시 추출해서 사용함으로써 해결한 기억이 있다.
사례에서 작업한 목표 아키텍처
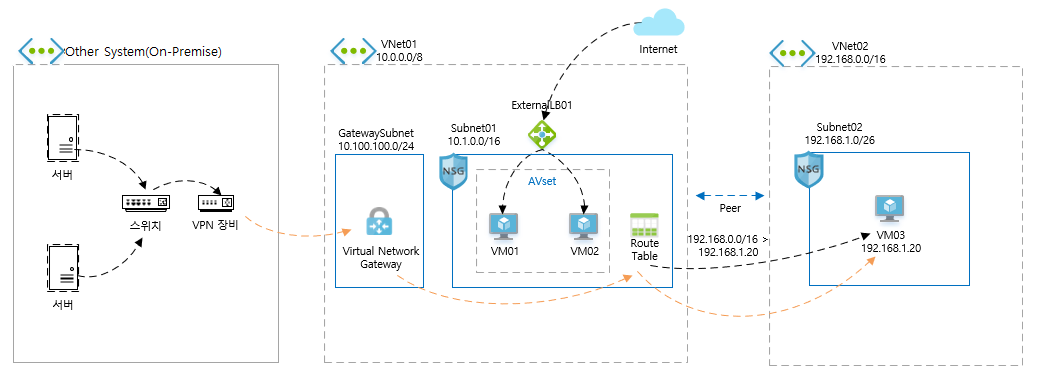
사례 링크 : https://github.com/hw038/Azure-Hands-On/tree/main/NO.5/Terraform
On-Premise 환경이 없었기에 Azure VNET 및 VPN을 따로 한 세트 더 만들어서 연동하는 작업을 수행했다.
이때, VPN를 생성하고 해당 Public IP를 output으로 추출 시 NULL값으로 추출되어 data source로 조회해서 사용.
2. 반복문
많은 개발언어에서도 그렇듯 반복문을 제공한다.
스터디의 내용을 가져와보자면,
list 형태의 값 목록이나 Key-Value 형태의 문자열 집합인 데이터가 있는 경우 동일한 내용에 대해 테라폼 구성 정의를 반복적으로 하지 않고 관리할 수 있다.
count : 반복문, 정수 값만큼 리소스나 모듈을 생성
for_each : 반복문, 선언된 key 값 개수만큼 리소스를 생성
for : 복합 형식 값의 형태를 변환하는 데 사용 ← for_each와 다름
dynamic : 리소스 내부 속성 블록을 동적인 블록으로 생성
count부터 실습해보자.
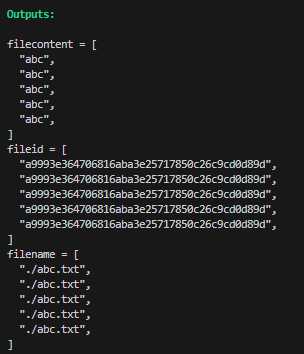
resource "local_file" "abc" {
count = 5
content = "abc"
filename = "${path.module}/abc.txt"
}
output "filecontent" {
value = local_file.abc.*.content
}
output "fileid" {
value = local_file.abc.*.id
}
output "filename" {
value = local_file.abc.*.filename
}
#
terraform init && terraform apply -auto-approve
terraform state list
terraform state show local_file.abc[0]
terraform state show local_file.abc[4] # 왜 정보 출력이 안되나요?
ls *.txt
#
terraform console
>
-----------------
local_file.abc
local_file.abc[0]
local_file.abc[4]
exit
-----------------
#
terraform output
terraform output filename
terraform output fileid
terraform output filecontent
main.tf 파일 수정 : count.index 값 추가
resource "local_file" "abc" {
count = 5
content = "abc${count.index}"
filename = "${path.module}/abc${count.index}.txt"
}
output "fileid" {
value = local_file.abc.*.id
}
output "filename" {
value = local_file.abc.*.filename
}
output "filecontent" {
value = local_file.abc.*.content
}실행 후 확인
#
terraform apply -auto-approve
terraform state list
ls *.txt
#
terraform console
>
-----------------
local_file.abc[0]
local_file.abc[4]
exit
-----------------
#
terraform output
terraform output filename
terraform output fileid
terraform output filecontent
# graph 확인 > graph.dot 파일 선택 후 오른쪽 상단 DOT 클릭
terraform graph > graph.dot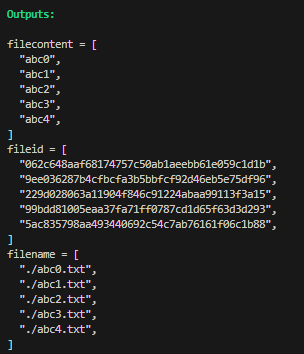
- count로 생성되는 리소스의 경우 <리소스 타입>.<이름>[<인덱스 번호>], 모듈의 경우 module.<모듈 이름>[<인덱스 번호>]로 해당 리소스의 값을 참조한다.
- 단, 모듈 내에 count 적용이 불가능한 선언이 있으므로 주의해야 한다.
- 예를 들어 provider 블록 선언부가 포함되어 있는 경우에는 count 적용이 불가능하다 → provider 분리
- 또한 외부 변수가 list 타입인 경우 중간에 값이 삭제되면 인덱스가 줄어들어 의도했던 중간 값에 대한 리소스만 삭제되는 것이 아니라 이후의 정의된 리소스들도 삭제되고 재생성된다. → 아래 실습으로 확인
이 부분을 쉽게 확인해보자.
variable "names" {
type = list(string)
default = ["a", "b", "c"]
}
resource "local_file" "abc" {
count = length(var.names)
content = "abc"
# 변수 인덱스에 직접 접근
filename = "${path.module}/abc-${var.names[count.index]}.txt"
}
resource "local_file" "def" {
count = length(var.names)
content = local_file.abc[count.index].content
# element function 활용
filename = "${path.module}/def-${element(var.names, count.index)}.txt"
}우선 a, b, c 리스트 형태로 담아서 리소스를 만든다.
그 후 입력 변수에서 b를 삭제한다.
variable "names" {
type = list(string)
default = ["a", "c"]
}이렇게되면 오브젝트 형태로 기억을 한다면 a와 c에 대한 리소스는 유지하고 b에 대한 리소스만 destroy가 나와야 한다.
terraform plan을 해보자.
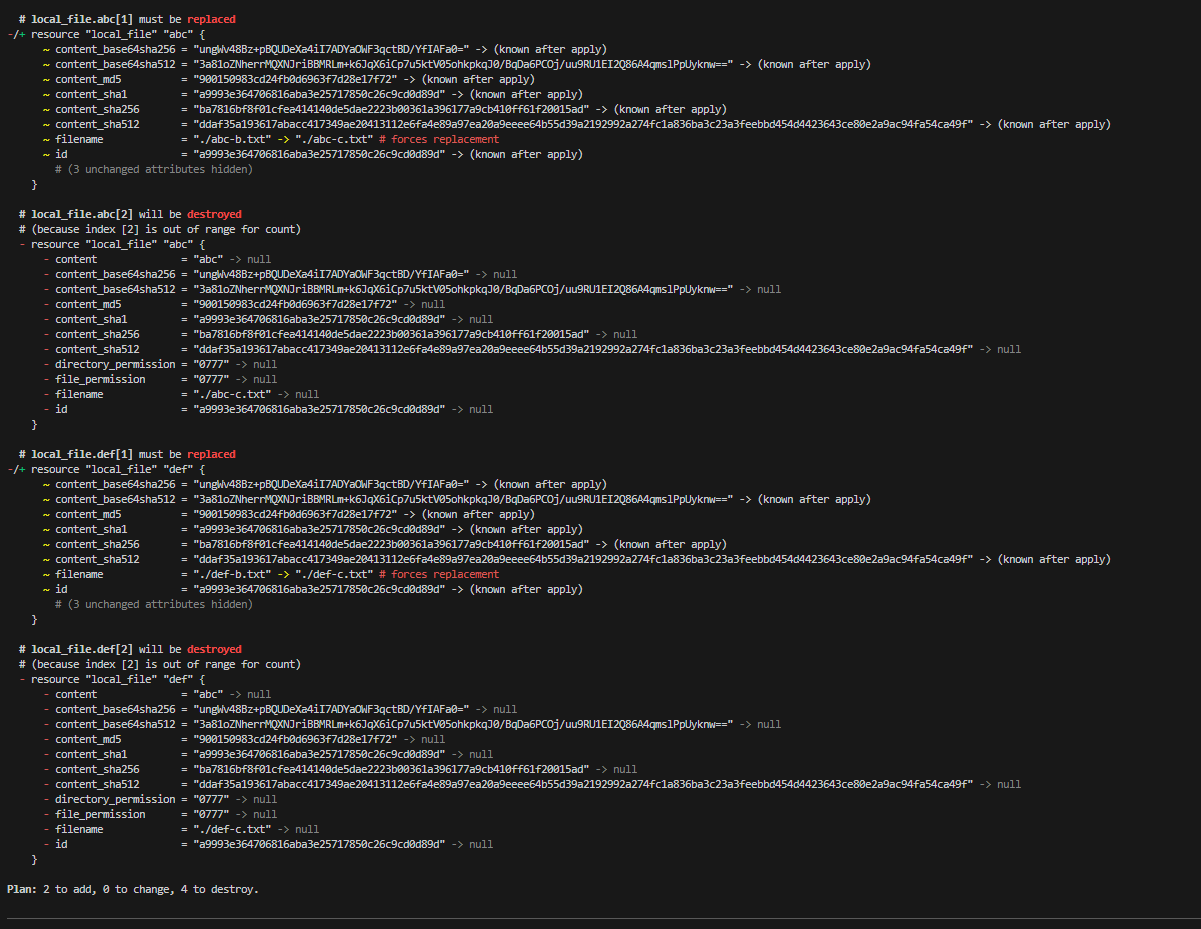
위에서 설명했듯이 리스트 형태로 단순히 카운팅하여 생성하기 때문에 1번 인덱스는 b -> c로 replaced 되며, 2번 인덱스는 destroyed 되는 것을 확인할 수 있다.
for_each
- 리소스 또는 모듈 블록에서 for_each에 입력된 데이터 형태가 map 또는 set이면, 선언된 key 값 개수만큼 리소스를 생성하게 된다.
- main.tf 파일 수정 : for_each 값이 있는 반복문 동작 확인
resource "local_file" "abc" {
for_each = {
a = "content a"
b = "content b"
}
content = each.value
filename = "${path.module}/${each.key}.txt"
}- 실행 후 확인
#
terraform apply -auto-approve
terraform state list
ls *.txt
cat a.txt ;echo
cat b.txt ;echo
#
terraform console
>
-----------------
local_file.abc
local_file.abc[a]
local_file.abc["a"]
exit
-----------------
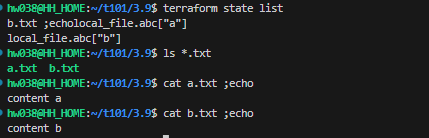
- for_each가 설정된 블록에서는 each 속성을 사용해 구성을 수정할 수 있다
- each.key : 이 인스턴스에 해당하는 map 타입의 key 값
- each.value : 이 인스턴스에 해당하는 map의 value 값
- 생성되는 리소스의 경우 <리소스 타입>.<이름>[<key>], 모듈의 경우 module.<모듈 이름>[<key>]로 해당 리소스의 값을 참조한다.
- 이 참조 방식을 통해 리소스 간 종송석을 정의하기도 하고 변수로 다른 리소스에서 사용하거나 출력을 위한 결과 값으로 사용한다.
- main.tf 파일 수정 : local_file.abc는 변수의 map 형태의 값을 참조, local_file.def의 경우 local_file.abc 도한 결과가 map으로 반환되므로 다시 for_each 구문을 사용할 수 있다
variable "names" {
default = {
a = "content a"
b = "content b"
c = "content c"
}
}
resource "local_file" "abc" {
for_each = var.names
content = each.value
filename = "${path.module}/abc-${each.key}.txt"
}
resource "local_file" "def" {
for_each = local_file.abc
content = each.value.content
filename = "${path.module}/def-${each.key}.txt"
}- 실행 후 확인
#
terraform apply -auto-approve
terraform state list
ls *.txt
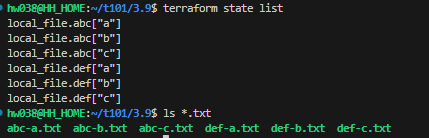
- key 값은 count의 index와는 달리 고유하므로 중간에 값을 삭제한 후 다시 적용해도 삭제한 값에 대해서만 리소스를 삭제한다.
- main.tf 파일 수정 : count 경우와 유사하게 중간 값을 삭제 후 확인
variable "names" {
default = {
a = "content a"
c = "content c"
}
}
resource "local_file" "abc" {
for_each = var.names
content = each.value
filename = "${path.module}/abc-${each.key}.txt"
}
resource "local_file" "def" {
for_each = local_file.abc
content = each.value.content
filename = "${path.module}/def-${each.key}.txt"
}- 실행 후 확인
#
terraform apply -auto-approve
terraform state list
ls *.txt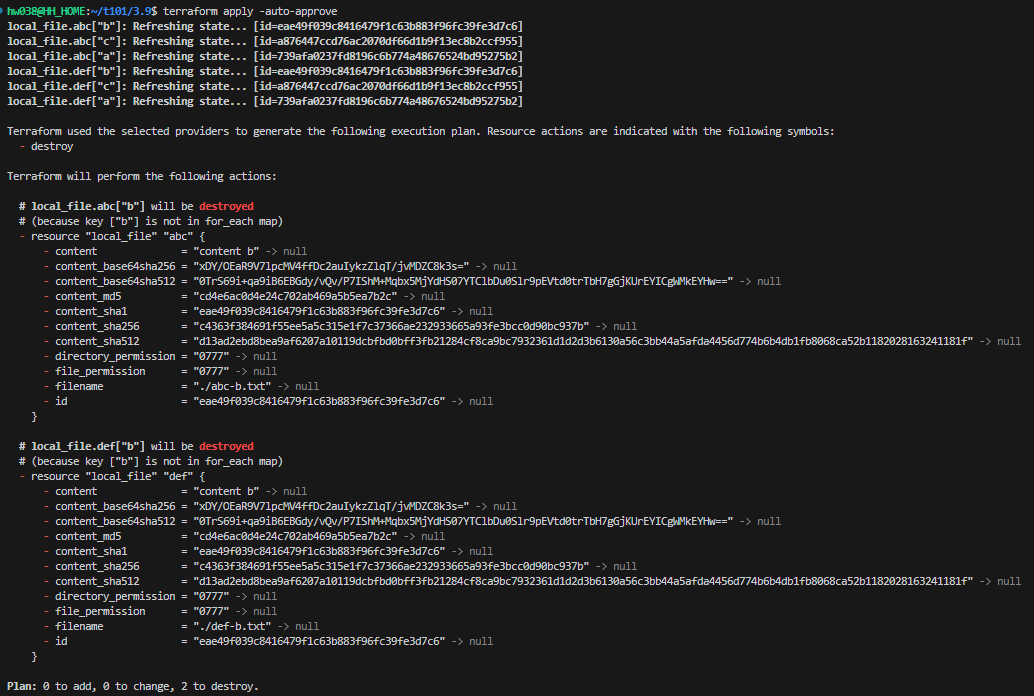
앞서 count와는 달리 b 오브젝트만 삭제하는 로직을 수행하게 된다.
for
- 예를 들어 list 값의 포맷을 변경하거나 특정 접두사 prefix를 추가할 수도 있고, output에 원하는 형태로 반복적인 결과를 표현할 수 도 있다.
- list 타입의 경우 값 또는 인덱스와 값을 반환
- map 타입의 경우 키 또는 키와 값에 대해 반환
- set 타입의 경우 키 값에 대해 반환
- main.tf 파일 수정 : list의 내용을 담는 리소스를 생성, var.name의 내용이 결과 파일에 content로 기록됨
variable "names" {
default = ["a", "b", "c"]
}
resource "local_file" "abc" {
content = jsonencode(var.names) # 결과 : ["a", "b", "c"]
filename = "${path.module}/abc.txt"
}- 실행 후 확인 : jsonencode Function - 링크
#
terraform apply -auto-approve
terraform state list
ls *.txt
cat abc.txt ;echo
# 참고 jsonencode Function
terraform console
>
-----------------
jsonencode({"hello"="world"})
{"hello":"world"}
exit
-----------------
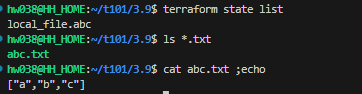
- 목표 : var.name 값을 일괄적으로 대문자로 변환!
- main.tf 파일 수정 : content의 값 정의에 for 구문을 사용하여 내부 값을 일괄적으로 변경
variable "names" {
default = ["a", "b", "c"]
}
resource "local_file" "abc" {
content = jsonencode([for s in var.names : upper(s)]) # 결과 : ["A", "B", "C"]
filename = "${path.module}/abc.txt"
}- 실행 후 확인 - title
#
terraform apply -auto-approve
terraform state list
ls *.txt
cat abc.txt ;echo
# 참고 jsonencode Function
terraform console
>
-----------------
jsonencode([for s in var.names : upper(s)])
[for s in var.names : upper(s)]
[for txt in var.names : upper(txt)]
title("hello world")
exit
------------------ for 구문을 사용하는 몇 가지 규칙은 다음과 같다
- list 유형의 경우 반환 받는 값이 하나로 되어 있으면 값을, 두 개의 경우 앞의 인수가 인덱스를 반환하고 뒤의 인수가 값을 반환
- 관용적으로 인덱스는 i, 값은 v로 표현
- map 유형의 경우 반환 받는 값이 하나로 되어 있으면 키를, 두 개의 경우 앞의 인수가 키를 반환하고 뒤의 인수가 값을 반환
- 관용적으로 키는 k, 값은 v로 표현
- 결과 값은 for 문을 묶는 기호가 **[ ]**인 경우 tuple로 반환되고 **{ }**인 경우 object 형태로 반환
- object 형태의 경우 키와 값에 대한 쌍은 ⇒ 기호로 구분
- { } 형식을 사용해 object 형태로 결과를 반환하는 경우 키 값은 고유해야 하므로 값 뒤에 그룹화 모드 심볼(…)를 붙여서 키의 중복을 방지(SQL의 group by 문 또는 Java의 MultiValueMap과 같은 개념)
- if 구문을 추가해 조건 부여 가능
- list 유형의 경우 반환 받는 값이 하나로 되어 있으면 값을, 두 개의 경우 앞의 인수가 인덱스를 반환하고 뒤의 인수가 값을 반환
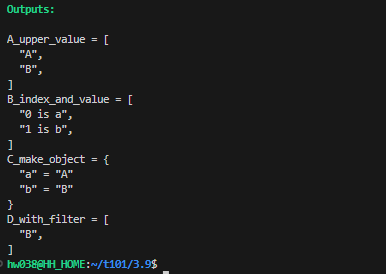
- main.tf 파일 수정 : list 유형에 대한 for 구문 처리의 몇 가지 예를 확인
variable "names" {
type = list(string)
default = ["a", "b"]
}
output "A_upper_value" {
value = [for v in var.names : upper(v)]
}
output "B_index_and_value" {
value = [for i, v in var.names : "${i} is ${v}"]
}
output "C_make_object" {
value = { for v in var.names : v => upper(v) }
}
output "D_with_filter" {
value = [for v in var.names : upper(v) if v != "a"]
}- 실행 후 확인
#
terraform apply -auto-approve
terraform state list
#
terraform output
terraform output A_upper_value
terraform output D_with_filter
#
terraform console
>
-----------------
var.names
[for v in var.names : upper(v)]
[for i, v in var.names : "${i} is ${v}"]
{ for v in var.names : v => upper(v) }
[for v in var.names : upper(v) if v != "a"]
exit
-----------------
- main.tf 파일 수정 : map 유형에 대한 for 구문 처리의 몇 가지 예를 확인
variable "members" {
type = map(object({
role = string
}))
default = {
ab = { role = "member", group = "dev" }
cd = { role = "admin", group = "dev" }
ef = { role = "member", group = "ops" }
}
}
output "A_to_tupple" {
value = [for k, v in var.members : "${k} is ${v.role}"]
}
output "B_get_only_role" {
value = {
for name, user in var.members : name => user.role
if user.role == "admin"
}
}
output "C_group" {
value = {
for name, user in var.members : user.role => name...
}
}- 실행 후 확인
#
terraform apply -auto-approve
terraform state list
#
terraform output
terraform output A_upper_value
#
terraform console
>
-----------------
var.members
[for k, v in var.members : "${k} is ${v.role}"]
{for name, user in var.members : name => user.role}
{for name, user in var.members : name => user.role if user.role == "admin"}
{for name, user in var.members : user.role => name...}
exit
-----------------음... 여기서부터 어마어마해진 것 같은데, 실무에서 유용할 것만 같은 구조다.
map 형태로 저장하고 이를 for문을 활용해서 원하는 데이터를 추출하는 작업을 수행한다.
나는 이 예제에서 ops group에 있는 user name을 추출하고 싶었다.
예제에서 C_group이 role을 기준으로 그루핑해서 보여주기만 했기 때문에 이 예제를 추가해보았다.
group에 대한 정보를 사용하려면 map object에 group을 추가해야 한다.
variable "members" {
type = map(object({
role = string
group = string
}))
default = {
user-ab = { role = "member", group = "dev" }
user-cd = { role = "admin", group = "dev" }
user-ef = { role = "member", group = "ops" }
user-netcloudy = { role = "admin", group = "ops" }
}
}
output "A_to_tupple" {
value = [for k, v in var.members : "${k} is ${v.role}"]
}
output "B_get_only_role" {
value = {
for name, user in var.members : name => user.role
if user.role == "member"
}
}
output "C_group" {
value = {
for name, user in var.members : user.role => name...
}
}
output "D_get_only_ops_group" {
value = {
for name, user in var.members : name => user.group
if user.group == "ops"
}
}실행 결과
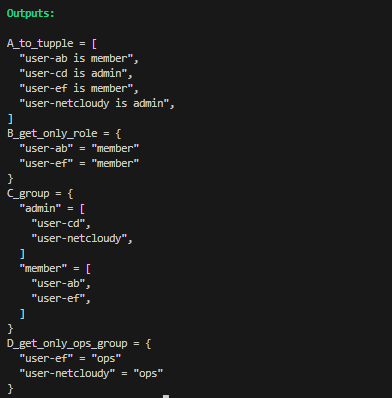
D_get_only_ops_group 을 확인해보면 ops group의 유저만 추출된 것을 확인할 수 있다.
Dynamic
- count 나 for_each 구문을 사용한 리소스 전체를 여러 개 생성하는 것 이외도 리소스 내에 선언되는 구성 블록을 다중으로 작성해야 하는 경우가 있다.
- 예를 들면 AWS Security Group 리소스 구성에 ingress, egress 요소가 리소스 선언 내부에서 블록 형태로 여러 번 정의되는 경우다.
resource "aws_security_group" "example" {
name = "example-security-group"
description = "Example security group"
vpc_id. = aws_vpc.main.id
ingress {
from_port = 22
to_port = 22
protocol = "tcp"
cidr_blocks = ["0.0.0.0/0"]
}
ingress {
from_port = 443
to_port = 443
protocol = "tcp"
ipv6_cidr_blocks = ["::/0"]
}
}- 리소스 내의 블록 속성(Attributes as Blocks)은 리소스 자체의 반복 선언이 아닌 내부 속성 요소 중 블록으로 표현되는 부분에 대해서만 반복 구문을 사용해야 하므로, 이때 dynamic 블록을 사용해 동적인 블록을 생성 할 수 있다.
- dynamic 블록을 작성하려면, 기존 블록의 속성 이름을 dynamic 블록의 이름으로 선언하고 기존 블록 속성에 정의되는 내용을 content 블록에 작성한다.
- 반복 선언에 사용되는 반복문 구문은 for_each를 사용한다. 기존 for_each 적용 시 each 속성에 key, value가 적용되었다면 dynamic에서는 dynamic에 지정한 이름에 대해 속성이 부여된다.
- dynamic 블록 활용 예
| 일반적인 블록 속성 반복 적용 시 | dynamic 블록 적용 시 |
|
resource "provider_resource" "name" {
name = "some_resource"
some_setting {
key = a_value
}
some_setting {
key = b_value
}
some_setting {
key = c_value
}
some_setting {
key = d_value
}
}
|
resource "provider_resource" "name" {
name = "some_resource"
dynamic "some_setting" {
for_each = {
a_key = a_value
b_key = b_value
c_key = c_value
d_key = d_value
}
content {
key = some_setting.value
}
}
}
|
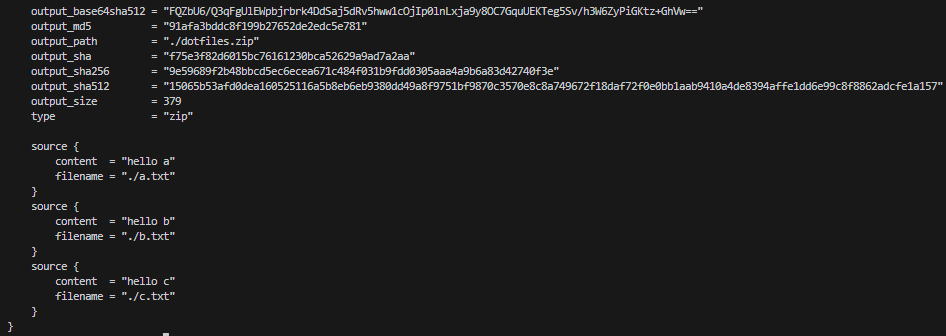
data "archive_file" "dotfiles" {
type = "zip"
output_path = "${path.module}/dotfiles.zip"
source {
content = "hello a"
filename = "${path.module}/a.txt"
}
source {
content = "hello b"
filename = "${path.module}/b.txt"
}
source {
content = "hello c"
filename = "${path.module}/c.txt"
}
}- 실행 후 확인
#
terraform init -upgrade
terraform apply -auto-approve
terraform state list
terraform state show data.archive_file.dotfiles
ls *.zip
unzip dotfiles.zip
ls *.txt
cat a.txt ; echo- main.tf 파일 수정 : 리소스 내에 반복 선언 구성을 dynamic 블록으로 재구성
variable "names" {
default = {
a = "hello a"
b = "hello b"
c = "hello c"
}
}
data "archive_file" "dotfiles" {
type = "zip"
output_path = "${path.module}/dotfiles.zip"
dynamic "source" {
for_each = var.names
content {
content = source.value
filename = "${path.module}/${source.key}.txt"
}
}
}- 실행 후 확인 : 동일한 결과가 기대되어 변경 사항이 없다!
#
terraform apply -auto-approve
terraform state list
terraform state show data.archive_file.dotfiles
ls *.zip
결론
데이터 소스와 count는 스터디 이전에 한번 사용해본 경험이 있어서 더 깊이 알 수 있게 되었고, 그 외에 다른 반복문의 경우도 활용처와 차이점을 잘 알게 되었다.
'Tech > Terraform' 카테고리의 다른 글
| [T101_3기] 3주차 - 기본 사용 및 프로바이더 (1/3) - 기본 사용(1/2) (0) | 2023.09.10 |
|---|---|
| [T101_3기] 2주차 - 기본 사용 (3/3) - 출력(output) (0) | 2023.09.09 |
| [T101_3기] 2주차 - 기본 사용 (2/3) - 입력 변수(Variable) 및 지역값(local) (0) | 2023.09.09 |
| [T101_3기] 1주차 - Terraform 설명 및 환경 구성 (2/2) - 도전 과제 (0) | 2023.09.01 |
| [T101_3기] 1주차 - Terraform 설명 및 환경 구성 (1/2) - 설명 및 구성 (0) | 2023.09.01 |




댓글